Agregación y desagregación
¿Qué es la (des)agregación?
La agregación es el proceso de agrupar observaciones para calcular datos resumidos para un área más grande. Por ejemplo, se podría sumar la población total en 3 bloques censales adyacentes para informar de la población total de un área en particular, como se muestra en la figura siguiente.
Agregación de la población en 3 bloques censales
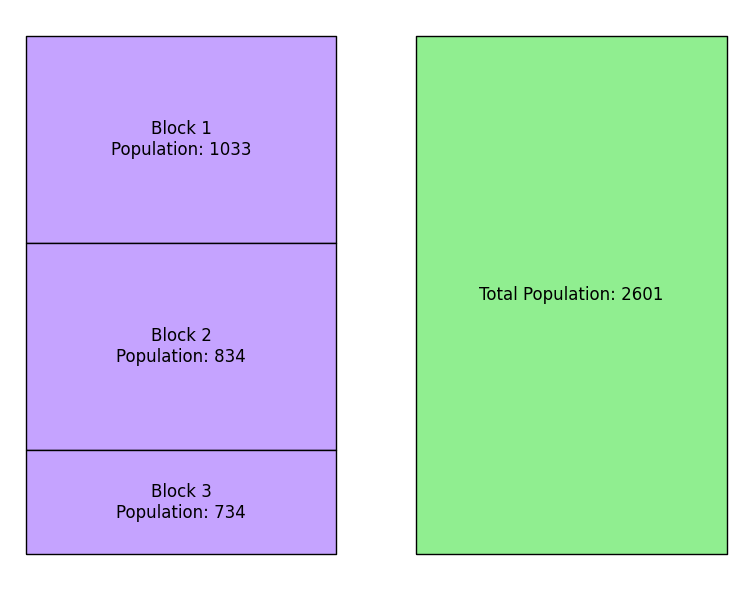
La desagregación es el proceso inverso de desglosar los datos agregados en unidades más pequeñas. Los datos desagregados siempre serán una estimación, como es el caso de desagregar los resultados de las elecciones de los distritos a los bloques censales.
Tanto en la agregación como en la desagregación, la unidad geográfica para la que se conocen los datos se denomina a menudo el origen, mientras que la unidad geográfica para la que se desean y se desconocen los datos se denomina el objetivo.
¿Por qué agregar y desagregar?
En la redistribución de distritos, a menudo se necesitan datos a niveles geográficos de los que no se dispone. Por ejemplo, se pueden desear datos a nivel de distrito, pero los datos del censo se reportan con frecuencia a nivel geográfico, como grupos de bloques o secciones censales, mientras que los datos electorales se reportan típicamente a nivel de distrito.
Debido a que estas geografías se cruzan en formas que dificultan la agregación directa de los datos, es necesario primero desagregar los resultados de las elecciones (generalmente a nivel de distrito) o datos demográficos (generalmente a nivel de grupo de bloques o tracto) a la unidad más pequeña posible: el nivel de bloque censal. Dado que los distritos legislativos estatales y del Congreso, y muchas otras geografías censales, se forman a partir de bloques censales, los datos pueden agregarse hasta el nivel de distrito.
Otra situación común que requiere agregación y desagregación es cuando se trata de analizar datos demográficos y electorales simultáneamente, como en el caso de los análisis de voto racialmente polarizado. Los datos del censo están disponibles en bloques censales (u otras geografías censales), que suelen ser más pequeños y a veces dividen las geografías de los distritos en los que se comunican los resultados de las elecciones. Como resultado, los datos del censo a nivel de bloque deben agregarse a los distritos o los datos electorales a nivel de distrito desagregados a bloques, para analizar ambos tipos de datos simultáneamente.
El rol de los datos espaciales en la asignación
Para (des)agregar, las geografías objetivo deben mapearse, o asignarse, a las geografías de origen. Este proceso puede ser de naturaleza espacial o no espacial.
En la asignación no espacial, la relación de las geografías objetivo con las geografías de origen se conoce de antemano. Por ejemplo, la Oficina del Censo ha ideado un sistema claro en el que los bloques censales anidan perfectamente dentro de los grupos de bloques, los grupos de bloques anidan perfectamente dentro de las secciones censales, las secciones censales anidan perfectamente dentro de los condados y los condados anidan perfectamente dentro de los estados. Esta asignación se identifica por valores de geocodificación. Debido a que se sabe qué bloques anidan en qué grupos de bloques (y así sucesivamente), no se requieren datos geoespaciales para agregar o desagregar estas geografías censales.
Asignación no espacial con datos del censo
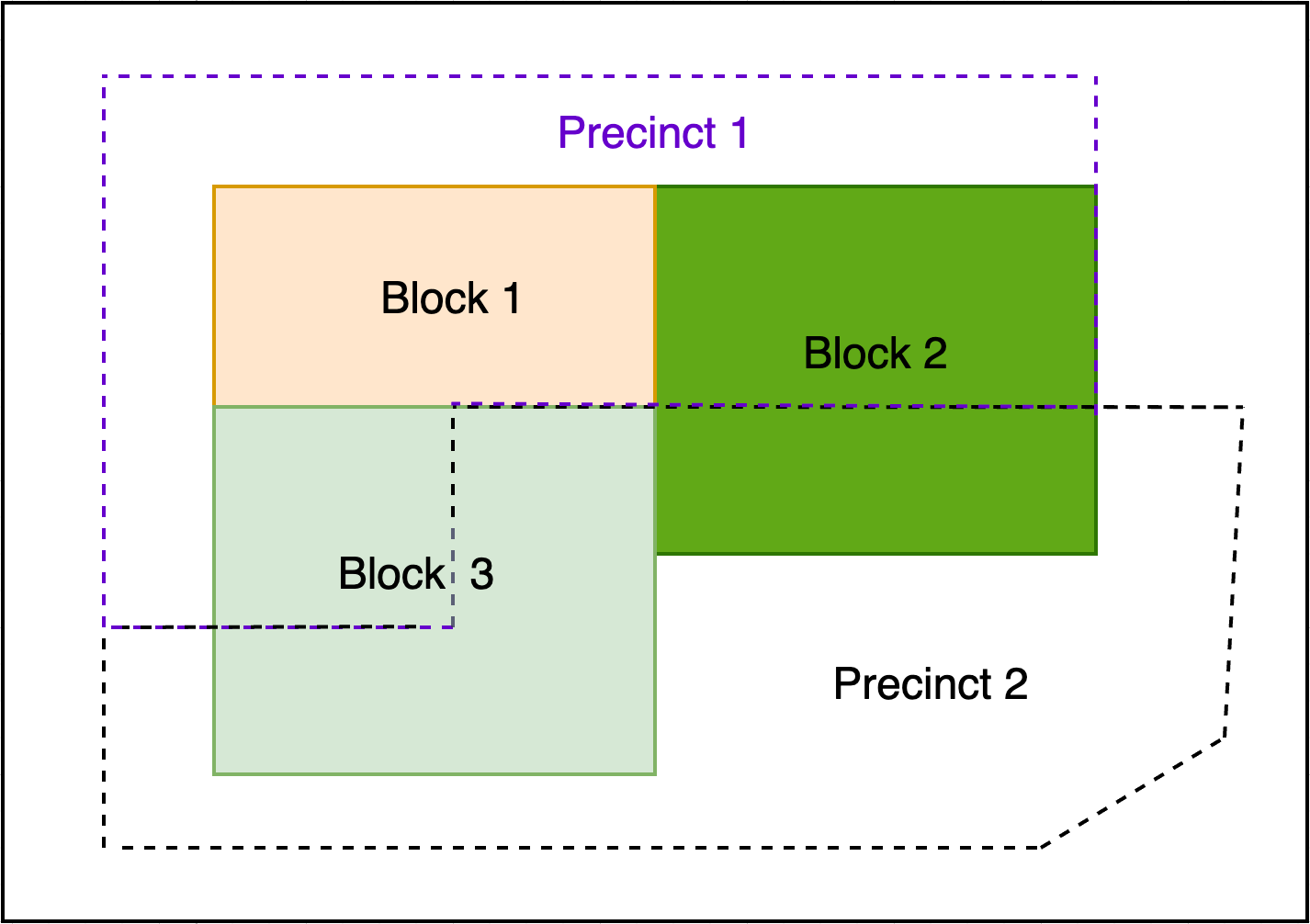
En la asignación espacial, la relación de las geografías objetivo con las geografías de origen no se conoce de antemano y se debe encontrar utilizando datos espaciales. Este es a menudo el caso cuando se trabaja con resultados de las elecciones a nivel de distrito y datos demográficos en bloques censales. Para agregar datos a nivel de bloque a los distritos, por ejemplo, los límites exactos de estos distritos deben conocerse y mapearse en comparación con los límites de los bloques, con el fin de asignar bloques apropiadamente y crear la agregación mejor estimada de los datos a nivel de distritos.
Algunos estados trabajan arduamente para alinear los bloques censales con los distritos, haciendo que el mapeo de la fuente a las geografías objetivo sea relativamente sencillo. Otros estados no lo hacen, sin embargo, y muchos distritos pueden estar divididos. También hay una gran variación en el grado o “seriedad” de la división, algunos distritos pueden dividir bloques muy ligeramente, y es más probable que se deba a la calidad de los datos que a un desajuste intencionado.
Asignación espacial de 3 bloques censales a 2 distritos
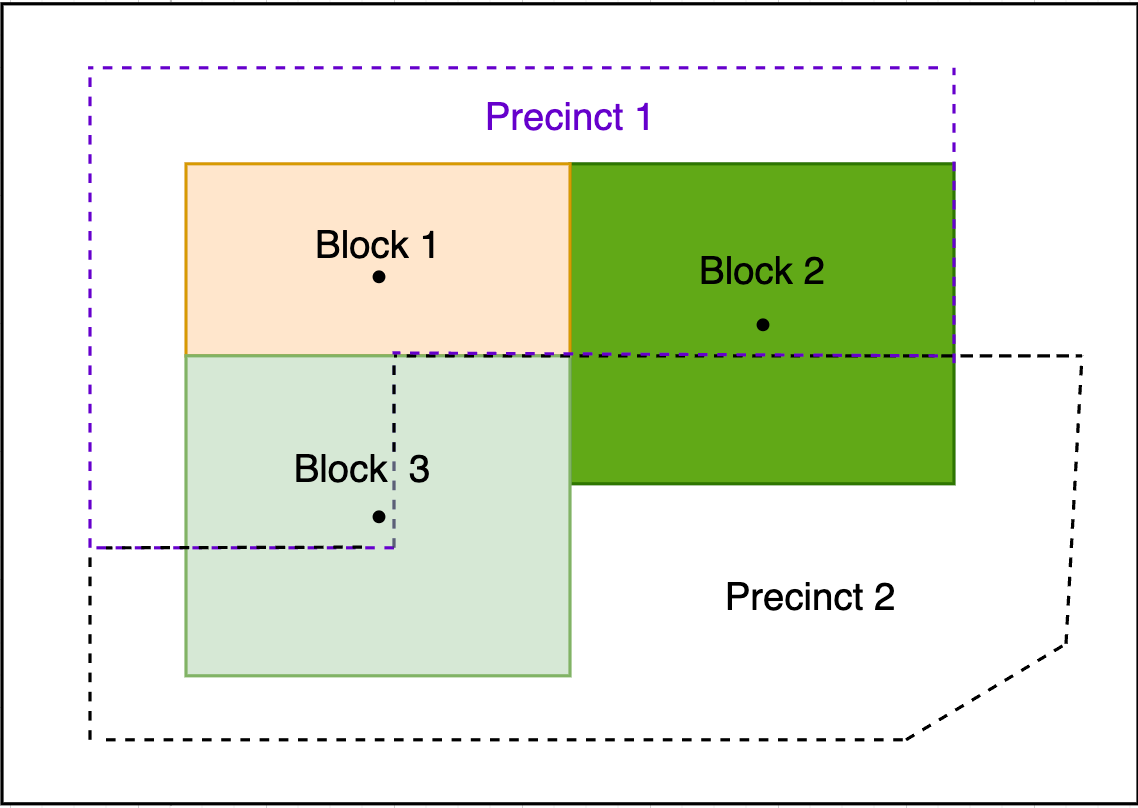
Una forma de asignar geografías de origen a geografías objetivo es usar el punto central geográfico de la fuente, conocido como el centroide. Por ejemplo, si el centroide de un bloque censal cae en un distrito particular, entonces ese bloque será asignado al distrito.
Asignar espacialmente bloques del censo a los distritos basados en centroides
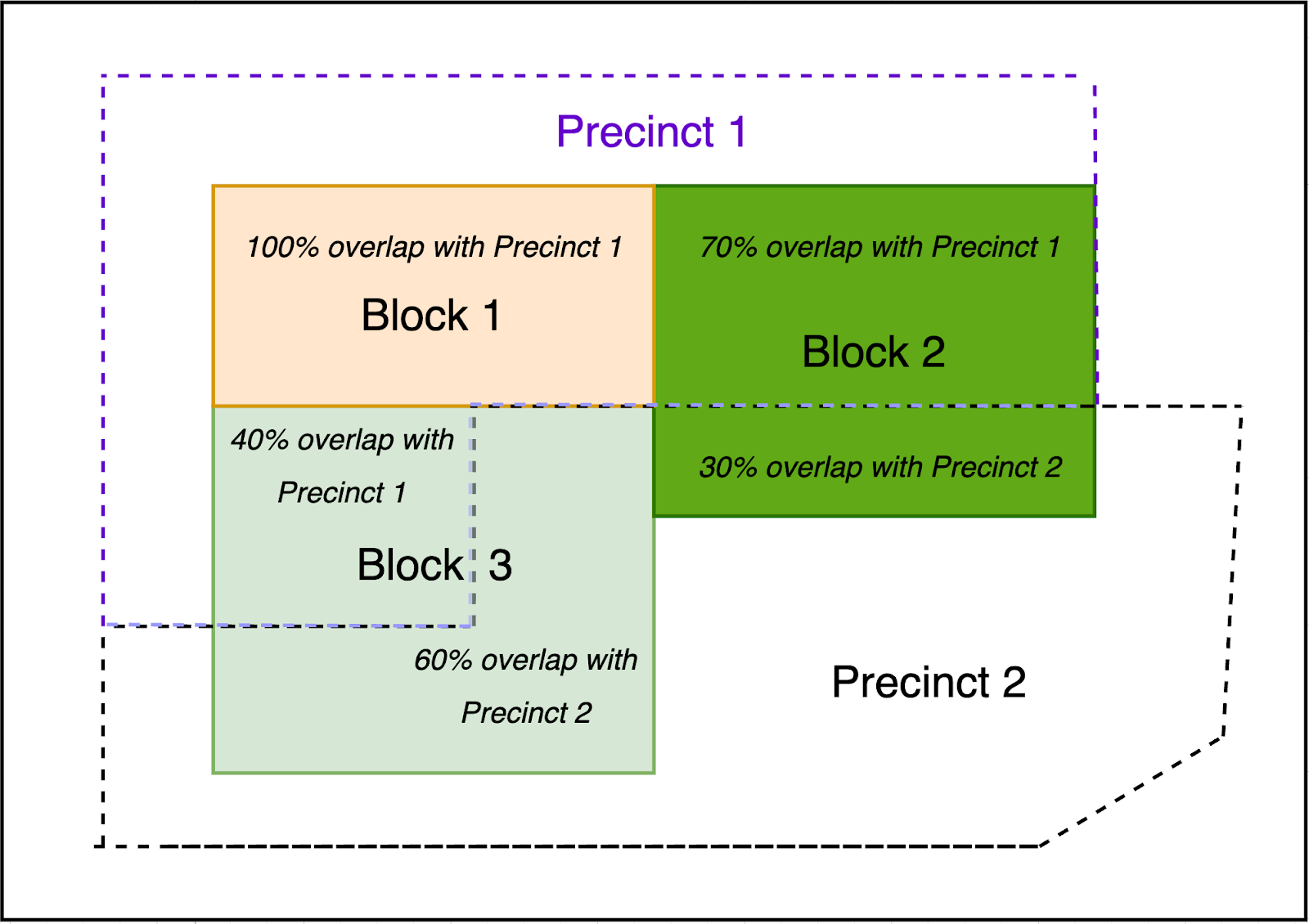
Otro método consiste en asignar fuentes a las geografías objetivo según la mayor superposición de área. Si el 60 % de una manzana se superpusiera con un distrito y el 40 % restante con otro, asignaríamos la manzana al distrito con el que comparte el 60 % de la misma geografía. Este es el método predeterminado del paquete de Python maup, creado por nuestro socio de datos. Grupo de Geometría Métrica y Gerrymandering.
Asignación espacial de bloques censales a distritos según la superposición de áreas
Cómo agregar o desagregar
Además de la asignación, se necesita información adicional sobre las geografías objetivo para estimar cómo deben distribuirse y desagregarse los datos de fuentes agregadas. Cuanto más precisa sea la información en la geografía objetivo que represente lo que está tratando de desagregar, mejor será la desagregación.
Matemáticamente, la desagregación es el proceso de resolver una ecuación donde dos proporciones son iguales entre sí, y usted está tratando de resolver X1:
Datos a nivel de bloque Y1 (conocido) Datos a nivel de grupo de bloque Y2 (conocido) = Datos a nivel de bloque X1 (desconocido) Datos a nivel de grupo de bloque X2 (conocido)
Por ejemplo, la Oficina del Censo publica datos de población ciudadana en edad de votar (CVAP), pero solo a nivel de grupo de bloques. Podemos utilizar los datos del censo 2020 PL 94-171 a nivel de bloques, que proporcionan recuentos de la población total, población total por raza/etnia, población total en edad de votar (VAP, o población de 18 años o más), y VAP por raza/etnia para desagregar los datos de CVAP.
Específicamente, el equipo de RDH utiliza recuentos de la población por raza/etnia de acuerdo con las 1997 categorías OMB para desagregar las estimaciones de grupo de bloque de CVAP por raza/etnia. Calculamos la relación de la VAP de cada bloque (por raza/etnia) en relación con la CVAP de cada grupo de bloques (por raza/etnia), y multiplicamos la población del grupo de bloques por esa relación para estimar la población en cada bloque, utilizando la ecuación anterior.
Para desagregar los resultados de las elecciones, el equipo de RDH utiliza una VAP modificada, que sustrae a la población encarcelada adulta (18 años o más) reportada en la tabla P5 de los datos del censo decenal PL 2020-94 de 171 de la VAP total.
Hay muchos desagregadores posibles, y lo más apropiado depende de cada conjunto de datos. Por ejemplo, el equipo de RDH ha utilizado datos sobre el número de hogares (para desagregar los datos de los hogares) y la población de 25 años y más (para desagregar el nivel educativo). También es posible desagregar los datos sobre la base de una combinación de factores: por ejemplo, si la VAP del censo decenal es el desagregador deseado, pero los datos a desagregar son de mediados de la década (digamos, 2015), se podría utilizar un promedio de los datos de VAP de 2010 y 2020.
Es importante entender que los datos desagregados darán lugar a menudo a valores fraccionarios. Por ejemplo, si un distrito tenía 3 votos que se desagregaron en dos bloques censales, uno podría terminar con 1.5 votos en cada uno. Por supuesto, no hay tal cosa como la mitad de un voto. Como tal, redondear estos valores es atractivo, para que los totales de votos “tengan sentido”. Pero si uno redondeara ciegamente usando el método habitual (cualquier cosa de 5 y más se redondea hacia arriba, cualquier cosa de 49 y por debajo se redondea hacia abajo), es fácil distorsionar los totales. En nuestro simple ejemplo, 1.5 se redondearía a 2, lo que da como resultado 4 votos a nivel de bloque censal, cuando solo 3 votos se emitieron a nivel de distrito. Afortunadamente, existen otros métodos de redondeo que evitan este tipo de distorsiones, como el método Hamilton, que utiliza el equipo de RDH, o el método de restos más grandes.
Para más detalles sobre el proceso, consulte nuestro código Python para desagregación electoral. El código de desagregación de varios conjuntos de datos también se puede encontrar en nuestra página de Github.
Supuestos en la (des)agregación y la asignación
Dependiendo de si uno está agregando o desagregando datos, y si uno está haciendo asignación espacial o no espacial, uno o más supuestos pueden estar involucrados en el proceso.
Cuando se agregan datos no espacialmente, es probable que no haya supuestos involucrados. Por ejemplo, la agregación de datos del censo de bloques a grupos de bloques no requiere suposiciones, ya que es simplemente una cuestión de sumar los datos de todas las geografías de origen para calcular los datos de la geografía objetivo.
Sin embargo, si la agregación es de naturaleza espacial, se asume que el método de asignación de geografías de origen a destino es correcto. Por ejemplo, si se agregaran datos sobre la población total de manzanas a distritos según la mayor superposición de área, se asumiría que todas las personas de esas manzanas deberían asignarse y contabilizarse en un distrito específico.
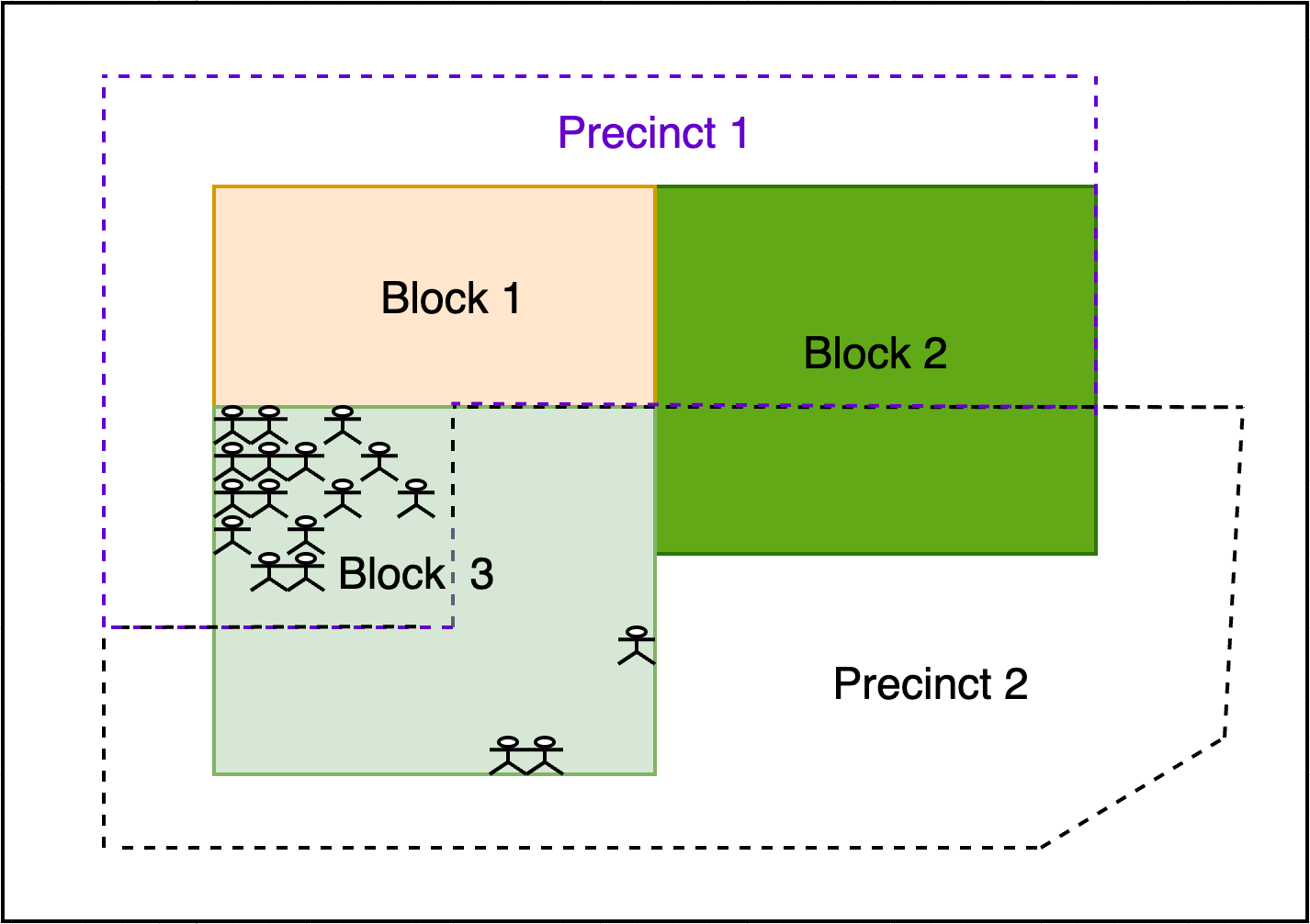
En la redistribución de distritos, la cuestión de interés suele centrarse en las personas o los votantes. Idealmente, la distribución espacial de la población en una manzana determinaría si se asignan las zonas de origen a las zonas objetivo según el centroide, la superposición de áreas o algún otro factor.
Sin embargo, estos datos de subbloques rara vez están disponibles. Los datos demográficos clave de la Oficina del Censo solo están disponibles a nivel de bloque censal o superior, y se desconoce exactamente dónde viven las personas dentro de un bloque. Los datos de dirección de los votantes están disponibles en los archivos de registro de votantes, pero comprarlos puede resultar prohibitivamente caro en algunos estados. Independientemente del costo, este enfoque requeriría un trabajo extenso para primero geocodificar a los votantes, luego cruzar sus direcciones con bloques censales y finalmente determinar la proporción de la población de cada bloque que vive en cada distrito.
El método de asignación espacial como presunción
La presunción de asignación correcta es necesaria tanto si se agregan como si se desagregan los datos. Pero hay un segundo conjunto de presunciones que se hacen al desagregar los datos específicamente, y es que a) la elección del desagregador es correcta, y b) la relación entre las dos proporciones es correcta.
Un buen ejemplo puede ser el uso de datos educativos. Si un estado publica datos a nivel de condado sobre la población total con títulos de licenciatura (BA/BS), uno podría estar interesado en desagregar esos datos a secciones del censo. La Oficina del Censo tiene datos educativos a nivel del área del censo, pero solo para personas de 25 años de edad o más. Como resultado, se podría establecer la siguiente ecuación para resolver X (la población con títulos de licenciatura en el nivel de la sección del censo):
Población de la sección del censo 25+ con título de licenciatura Población del condado 25+ con título de licenciatura = X Población del condado con título de licenciatura
Esta ecuación asume que la relación entre las poblaciones del condado y de la sección censal de 25 años de edad y mayores, y la relación entre las poblaciones del condado y de la sección censal con un título de licenciatura, son iguales entre sí, y que la opción de usar la población de la sección censal de 25 años y más con un título de licenciatura es el desagregador correcto. En última instancia, estas suposiciones pueden ser correctas en ciertas situaciones e incorrectas en otras.
de calidad
Verificamos nuestra agregación y desagregación resumiendo los totales de las geografías (des)agregadas para asegurarnos de que coincidan con los valores originales sumados. Si hay vacíos o solapamientos entre las geografías de origen y objetivo, el proceso de asignación puede fallar y se pueden perder datos. Como resultado, es muy importante asegurarse de que todos los datos se conservan durante el proceso de (des)agregación. Una vez confirmado esto, ahora podemos analizar estos datos, o unirlos a otros conjuntos de datos disponibles en la misma unidad de geografía.
¿Preguntas sobre (des)agregación?
Nuestro equipo de mesa de ayuda está aquí para ayudar.
Envíe un mensaje y le responderán en un día hábil.